To answer this, let us first explain the difference between frontend vs backend.
Our default recovery method, creates websites so that they look the same as on archive.org. This is the frontend. Roughly speaking, the code that generates all visible parts of a site is called the frontend.
However, most websites also have objects that require user-interaction. Some examples of these objects are: a contact form, a login section, a forum, a WordPress dashboard, post comments, a CMS admin panel etc. These objects with user-interaction require backend code.
Roughly speaking, the backend is the part of a website that takes care of the “invisible” logic, which is necessary to make interactive and dynamic objects work.
The backend code is generally required for anything that has user-interaction, contains private information (such as a password) or is highly dynamic or personalized (such as a Facebook news feed). Backend code is only visible for people with access to the hosting account of the original website. Backend code is not accessible to anonymous website visitors, or webscrapers.
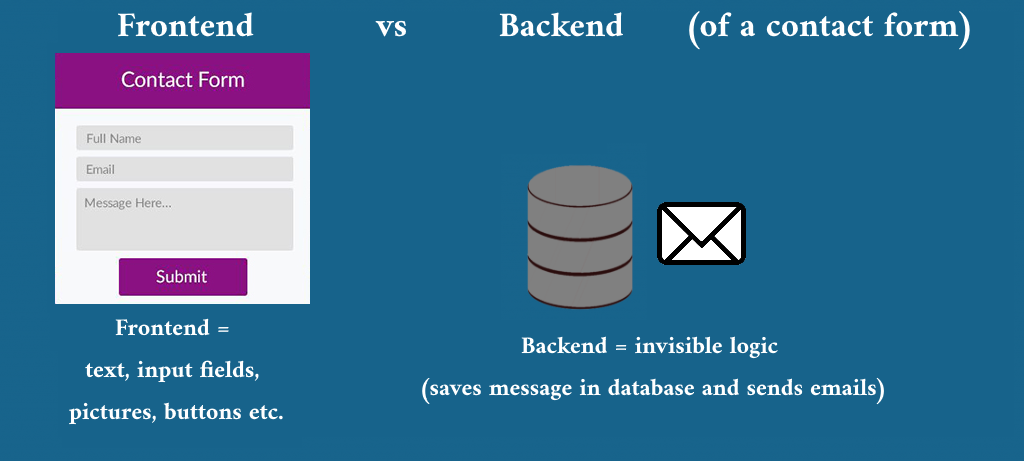
For example, a contact form both has a frontend part (the visible text fields and buttons) and a backend part (the invisible part that sends automatic emails and saves the message for the site owner). With our default orders, we recover the frontend, so the text fields and buttons look the same. However, nothing will happen when a user clicks on the “send” button. That would require backend code, which we can only add manually on a custom basis.
Examples of sites relying mostly on backend or frontend
Frontend. For a site without much user-interaction, such as a news website or an informational blog, our default method of website recovery gives great results. A news website doesn’t have much user-interaction, so it mostly uses frontend code. However, the contact form and the admin panel for such a site won’t be recovered, because those objects require backend code.
Backend. A site such as a currency-trading market place, heavily relies on backend code. Almost every object on such a site requires backend logic (think about the login process, buy/sell buttons, contact forms, frequently/dynamically updated prices, etc). Our default scraper won’t give good results.
Can you recover my backend files?
“Can you recover my backend files, such as my database file or PHP/ASP files?”
We receive questions like this at least once per week. The short answer to the question is: “no” (although our WordPress conversion is an exception in some way as you can read below).
What is the difference between frontend and backend files?
A backend file cannot be seen by website visitors. That is the entire definition of the concept “backend”. For example, a website visitor cannot download the database or PHP files of that website. A web scraper has the same limitations as a normal visitor. Therefore a webscraper cannot download those files either. A visitor or webscraper can only download frontend files, such as JavaScript*, HTML/CSS and pictures.

So a webscraper has no access to the backend of a website. Neither does it have access to a part of the website that is protected by a login process, such as domain.com/wp-login.php. (With our WordPress conversion, we do create a new /wp-login.php. More about that below)
The Wayback Machine also uses a web scraper to create all the websites on archive.org. The Wayback Machine therefore also never had access to the backend of any domain. And if a file is not on archive.org, then we obviously cannot recover it either.
This also means that any functionality of a page that connects to the backend, will not function correctly anymore either, after scraping that page. For example, a contact form needs to connect to the database (=backend) to store data about the message and other inputs. Maybe it also uses other backend files to send automatic emails to the website administrator. The result is that a contact form on a scraped website won’t work anymore as before. However, it will still look exactly the same as before.
Some URLs end in .PHP or .ASP. This doesn’t mean that a website user/scraper can download those files. It’s only possible to see the response that was created by those files. This response is normally an HTML file – even though the URL ends with .PHP/ASP. The result is that that we cannot recover the original PHP/ASP files and all of their functionality from the Wayback Machine. We only recover the layout/looks of those pages.

About our WordPress conversion
If you order our HTML to WordPress conversion, then we do reverse engineer a new “backend” based on the scraped HTML files. We then create a new WordPress dashboard which you can access as before on domain.com/wp-login.php. This new dashboard doesn’t have all the options (such as theme options, to change colors and widgets etc) but it does allow you to edit the current content in a visual WYSIWYG editor. It’s especially useful for people who don’t want to edit HTML code.
For the WordPress conversion, we also reverse-engineer a new MySQL database. However, such a WordPress conversion not perfect. For example, your old contact form will look the same, but won’t work anymore. We can fix contact forms for an additional price or you can manually do this yourself. With our WordPress conversion, pages merely look the same, and it allows you to edit content easily without requiring knowledge of HTML code.
*Modern websites also use JavaScript in the backend in the form of NodeJS, but historically .js files are only used in the frontend.